 Jun 4 2026
Jun 4 2026 Advanced 3D Medical Image Segmentation
Advanced 3D Medical Image Segmentation
AI Imaging Endpoints in Clinical Trials: How Annotation Quality Determines Trial Success
When a clinical trial fails, the instinct is to blame the drug. But in the age of AI-powered imaging endpoints, the culprit is increasingly the data, specifically, poorly annotated imaging data that corrupts the AI models used to measure trial outcomes.
This post examines how annotation quality in clinical AI trials directly determines whether an AI imaging endpoint can hold up to regulatory scrutiny, and how teams building oncology AI, neurology AI, or cardiology imaging tools can protect their trials from data-quality failures.
What Are AI Imaging Endpoints?
An imaging endpoint is a measurable, image-derived signal used to evaluate efficacy in a clinical trial. Traditional examples include tumor size measured by RECIST criteria. In modern AI-assisted trials, these endpoints are generated or validated by machine learning models trained on annotated imaging data.
AI imaging endpoints may include:
- Tumor volume segmentation across longitudinal CT scans
- Lesion burden mapping on PET/MRI in oncology
- White matter hyperintensity quantification in neurology trials
- Cardiac ejection fraction estimates in cardiology studies
In each case, the AI model’s output is only as reliable as the annotated dataset it was trained and validated on.
The Annotation Quality Problem Nobody Talks About
Here is the uncomfortable truth: most imaging AI products used in clinical research trace their performance failures not to model architecture, but to labeling inconsistencies in training data.
Inter-rater variability:where two annotators label the same lesion differently, can introduce systematic bias. If the training data is biased, the model will be biased. And in a clinical trial, biased AI outputs can invalidate endpoints entirely.
Consider a Phase II oncology trial measuring tumor response rate via an AI model. If the model was trained on annotations where boundary delineation varied by even 10–15%, the delta between responder and non-responder classifications may fall within that noise floor, making the endpoint meaningless.
| 💡 Key Insight
The FDA’s guidance on AI/ML-based Software as a Medical Device (SaMD) explicitly flags training data quality as a primary risk factor. Poor annotation is not a technical footnote, it is a regulatory liability. |
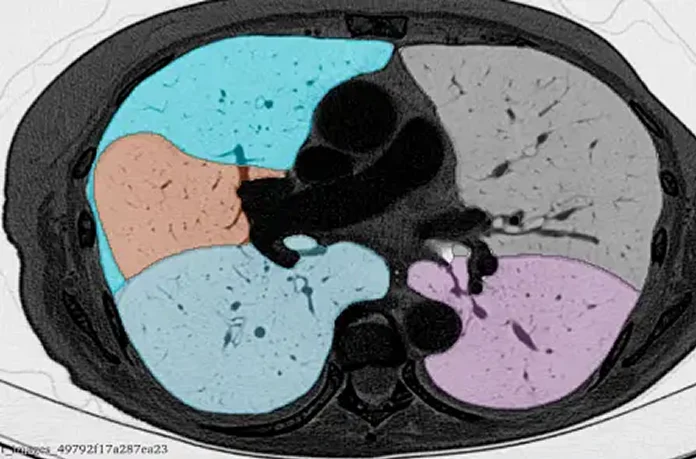
Five Ways Poor Annotation Kills Clinical Trial Imaging Endpoints
1. RECIST Non-Compliance in Lesion Labeling
RECIST 1.1-compliant annotation is a strict standard. Annotators must correctly classify target vs. non-target lesions, measure the longest diameter in the axial plane, and consistently handle confluent masses. Untrained annotators, or annotators without clinical context, routinely violate these rules, corrupting the ground truth for any AI model trained to replicate RECIST judgments.
2. Modality-Specific Inconsistencies
CT, MRI, PET, and ultrasound each have distinct intensity profiles, artifacts, and anatomical representations. An annotator trained primarily on CT cannot reliably label MRI data without modality-specific retraining. Mixed-modality annotation inconsistencies are a frequent and underreported source of model degradation in multimodal trial imaging.
3. Longitudinal Drift
In longitudinal trials, where the same patient is imaged at baseline, mid-treatment, and follow-up, annotators must apply consistent criteria across timepoints. Annotation drift occurs when criteria subtly shift across sessions, creating false signals of disease progression or response that contaminate endpoint data.
4. Inadequate Quality Control Pipelines
Many annotation vendors apply only surface-level QC: a supervisor reviews a sample of cases. Rigorous multi-layered QC in medical imaging annotation requires independent re-annotation, adjudication workflows for disagreements, and statistical inter-rater reliability metrics (such as Dice coefficients or Cohen’s Kappa). Without these, errors compound silently.
5. Missing Clinical Context
AI models used in clinical trials often segment pathological structures, tumors, plaques, and lesions that require clinical judgment to identify correctly. Annotators without domain expertise in radiology or clinical oncology will miss subtle findings, mislabel anatomy, or apply incorrect inclusion/exclusion criteria, all of which distort the model’s training signal.
What Good Annotation for Clinical AI Looks Like
High-quality annotation for clinical trial imaging endpoints should include:
- Annotators with domain training in the relevant modality and pathology (e.g., radiologists or trained clinicians for oncology segmentation)
- Clearly drafted SOPs with explicit inclusion/exclusion criteria per imaging timepoint
- Independent double-annotation followed by adjudication for discrepant cases
- Inter-rater reliability reporting using quantitative metrics (Dice, IoU, Cohen’s Kappa)
- Audit trails and version control for all annotation decisions, critical for regulatory submissions
- Modality-specific annotation workflows for CT, MRI, PET, and Ultrasound
How Pareidolia Systems Supports Clinical AI Imaging
At Pareidolia Systems, we provide high-precision medical image segmentation and annotation services built around the exact requirements of clinical AI development. Our annotators are trained across anatomical regions and imaging modalities, from oncology CT segmentation to neurology MRI labeling, and every dataset undergoes multi-layered quality assurance before delivery.
We work directly from client-submitted datasets, draft detailed SOPs in collaboration with your team, and deliver fully audit-ready annotation packages with inter-rater metrics included. Our 24/7 availability and transparent communication model mean you always know the status of your annotation pipeline, no black boxes, no surprises.
| 🏥 Pareidolia Systems, We Annotate. You Innovate.
From RECIST-compliant lesion labeling to complex 3D organ segmentation for multimodal oncology AI, our expert annotation teams ensure your clinical imaging AI is built on data that holds up under regulatory scrutiny. Visit www.pareidolia.in to schedule a free consultation. |
Conclusion
In AI-driven clinical trials, imaging endpoint validity lives or dies on annotation quality. The investment in rigorous, domain-expert annotation, with multi-layered QC, clear SOPs, and audit-ready documentation, is not overhead. It is the foundation of a trial that can produce meaningful, defensible evidence.
If your clinical AI program relies on imaging endpoints, the question is not whether annotation quality matters. It is whether you have the right annotation partner.