Jun 23 2026
Jun 23 2026 medical image analysis
medical image analysis
Why most medical image segmentation vendors fail at QC
Medical image segmentation quality control remains one of the industry’s biggest challenges. Not a shortage of annotation vendors, there are hundreds. Not a shortage of tools; annotation platforms proliferate. The problem is systemic: most vendors treat QC as a checkbox, not a process. And in medical image segmentation, that distinction is the difference between a model that performs and one that fails in deployment.
This post dissects why medical image segmentation QC fails at most vendors, what the failure modes look like in practice, and what genuine multi-layer quality assurance actually requires.
The QC Illusion: What Most Vendors Actually Do
When a segmentation vendor says they have “rigorous quality control,” the reality at most organizations is one or more of the following:
- Single-pass supervisor review: A team lead reviews a percentage of completed cases, often 10–20%, looking for obvious errors. This is not QC; it is sampling. Systematic errors that appear in the reviewed cases are corrected; those outside the sample propagate.
- Automated boundary checks: Some vendors use automated scripts to flag annotations where boundaries fall outside expected anatomical ranges. These catch gross errors but miss subtle segmentation inaccuracies, protocol deviations, and clinically incorrect label assignments.
- Client-side review: Some vendors rely on the client’s team to identify and flag quality issues after delivery. This is not a vendor QC process; it is cost externalization.
None of these approaches constitutes genuine multi-layer quality assurance in medical imaging. They are process proxies that look like QC on a proposal but fail when the stakes are high.

The Six Root Causes of Medical Image Segmentation QC Failure
1. Annotators Without Clinical Domain Knowledge
Medical image segmentation requires the annotator to understand what they are looking at. A lung nodule on a CT scan looks different from a vessel cross-section, a rib artifact, or pleural thickening, and the differences matter diagnostically. Annotators without clinical training or supervised domain-specific onboarding will make structurally incorrect labels that no automated QC system will catch.
2. No Formal Inter-Rater Reliability Measurement
Inter-rater reliability (IRR) is the statistical measure of agreement between annotators on the same case. In medical segmentation, this is typically measured with the Dice Similarity Coefficient (DSC), Hausdorff Distance, or Cohen’s Kappa for classification labels. Vendors without formal IRR measurement have no objective basis for claiming annotation consistency, and no way to detect systematic divergence between annotators over time.
3. Absence of Adjudication Workflows
Even expert annotators disagree. A genuine QC process requires a formal adjudication workflow: when two annotators produce discrepant segmentations of the same structure, the disagreement is escalated to a senior annotator or clinical reviewer who resolves it based on defined criteria. Without adjudication, discrepant cases are either handed off arbitrarily or averaged in ways that distort the ground truth.
4. Protocol Drift Across Long Annotation Runs
Annotation protocol drift is a time-dependent problem. Annotators who begin a large-volume project with tight SOP compliance may subtly relax criteria over weeks, boundaries become less precise, exclusion cases are treated more liberally, and edge cases get resolved inconsistently. Without periodic recalibration sessions and longitudinal IRR tracking, this drift is invisible until a model trained on the dataset underperforms.
5. Inadequate Modality-Specific SOPs
A segmentation SOP written for CT does not translate to MRI. T1 vs T2 weighting, FLAIR sequences, and contrast enhancement patterns each require specific annotation guidance. Vendors who apply generic SOPs across modalities introduce systematic labeling errors that vary by sequence type, contaminating datasets intended for multimodal model training.
6. No Audit Trail for Regulatory-Track Projects
For AI products on a regulatory pathway (FDA, CE Mark, CDSCO), annotation data must be auditable: who annotated each case, when, against which version of the SOP, and what QC review was applied. Most vendors cannot produce this documentation. This is not a minor gap; it can block a regulatory submission entirely.
| ⚠️ Critical Warning
If your annotation vendor cannot provide Dice Similarity Coefficients or Cohen’s Kappa scores from their QC process, quantified inter-rater reliability across annotators, case-level audit logs with annotator IDs and timestamps, and version-controlled SOP documentation, they are not doing real QC. They are doing record-keeping. |
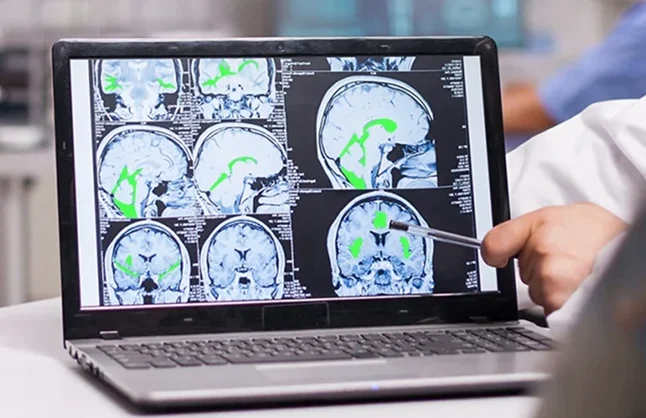
What Genuine Multi-Layer QC Looks Like
Rigorous QC for medical image segmentation requires:
- Independent double-annotation on a statistically significant sample, not just supervisor spot-checks
- Automated structural QC to flag anatomically implausible boundaries or missing structures
- Systematic IRR measurement reported at both the dataset and annotator level
- Formal adjudication protocols for discrepant cases with documented resolution
- Periodic recalibration sessions, at least monthly for long annotation runs, with annotators reviewing and discussing edge cases together
- Modality-specific SOP libraries with versioning and change documentation
- Case-level audit trails exportable for regulatory submissions
How to Evaluate an Image Segmentation Quality Control
Before selecting a vendor for clinical or regulatory-track annotation, ask these questions directly:
- What is your IRR measurement protocol, and what DSC thresholds do you require before releasing a dataset?
- How do you handle cases where two annotators produce significantly different segmentations?
- Can you provide a sample QC report with case-level metrics from a completed project?
- What is your process for detecting and correcting annotation protocol drift over a long project run?
- Do you maintain case-level audit logs suitable for regulatory submissions?
A vendor who cannot answer these questions clearly has not built real QC into their process.
Pareidolia Systems: QC Built Into Every Layer
Pareidolia Systems was built around the understanding that quality control in medical imaging annotation is not a step at the end of the pipeline, it is woven into every stage. Our annotators are trained to clinical standards across anatomical regions and modalities. Every dataset undergoes multi-layered QA, with IRR metrics reported and adjudication workflows applied to all discrepant cases.
We co-develop SOPs with your team, version-control all annotation guidelines, and deliver case-level audit documentation suitable for regulatory review. Our quality process is not a feature; it is the foundation of everything we produce.
| 🏥 Pareidolia Systems, We Annotate. You Innovate.
Precision is second nature at Pareidolia Systems. Whether you need pixel-accurate tumor segmentation, organ delineation, or complex 3D structure labeling, our QC pipeline is built to meet clinical and regulatory standards. Visit pareidolia.in to learn more. |
Conclusion
Most medical image segmentation vendors fail at QC, not because they are dishonest about their process, but because the industry has tolerated low standards. Single-pass review, informal protocols, and absent audit trails have become the norm, and medical AI teams pay the price in model failures, regulatory setbacks, and costly reannotation.
The bar for segmentation annotation quality control needs to be set by the clinical and regulatory context of the AI being built. If your AI product will eventually touch patient decisions, your annotation process must be held to the same rigor. Demand evidence of real QC from every vendor you evaluate.