 Jun 25 2026
Jun 25 2026 AI MRI cancer
AI MRI cancer
AI MRI Cancer Detection:Solving the Imaging Data Gap in Multimodal Oncology AI
AI MRI cancer detection is one of the most actively funded and most frequently overpromised areas in oncology technology. Deep learning models for MRI-based tumor detection, response assessment, and survival prediction are proliferating in academic literature. Very few of them survive contact with clinical deployment.
The reason is not algorithmic. The architecture is rarely the bottleneck. The bottleneck is the MRI imaging data that those models are trained on, how it is annotated, how consistently, and whether it reflects the full complexity of what radiologists actually interpret when they read an oncology MRI.
This article examines that gap: what AI MRI cancer detection actually requires at the data level, where most programs fail, and what it takes to build an annotation infrastructure that produces clinically reliable models.
What does AI MRI cancer detection actually require?
A deep learning model for MRI-based cancer detection or response assessment is not a single model. In practice, it is a pipeline that must handle:
- Multi-sequence MRI input: T1-weighted, T2-weighted, diffusion-weighted imaging (DWI), apparent diffusion coefficient (ADC) maps, and dynamic contrast-enhanced MRI (DCE-MRI) sequences, often all from the same exam, each requiring sequence-specific annotation conventions
- Tumor segmentation: Precise delineation of gross tumor volume (GTV), clinical target volume (CTV), and, in some applications, sub-regions such as necrosis, edema, and enhancing margin, each with distinct biological and prognostic significance
- Quantitative MRI biomarkers: ADC values for diffusion restriction, T2 signal ratios, DCE-MRI kinetic parameters (Ktrans, Ve), all derived from annotations, not raw images
- Multi-timepoint data: Baseline, mid-treatment, and follow-up MRI scans with annotations that are temporally consistent so the model can learn progression and response patterns
- Cross-modal integration: In multimodal oncology AI, MRI data must be fused with PET, CT, pathology, and genomic covariates, requiring annotations that are spatially and semantically compatible across modalities
MRI is the highest-dimensional, most sequence-complex, and most annotation-intensive modality in oncology imaging. A model that cannot handle MRI annotation depth cannot handle multimodal oncology AI.
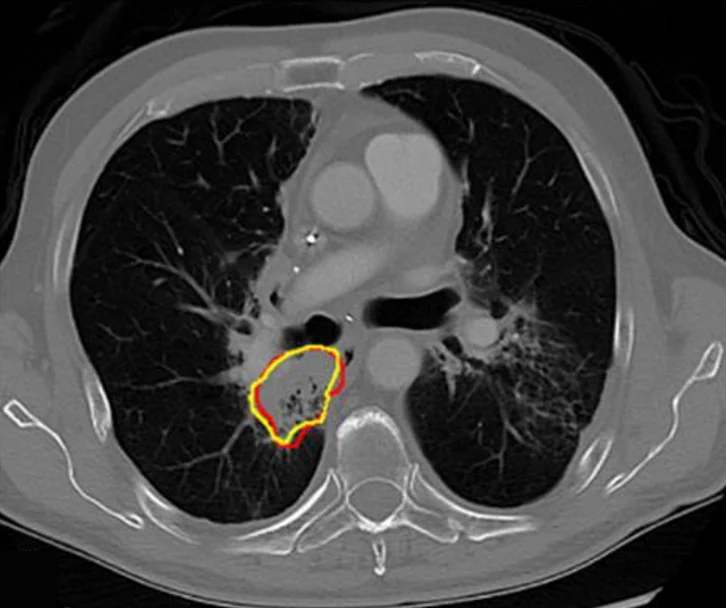
The four annotation dimensions that determine MRI AI model quality
1. Volume: Prioritize Annotated Cases Over Raw Scan Count
Successful MRI AI models are built on annotated cases, not raw scans. Brain tumors, prostate cancer, breast lesions, and liver tumors each require dedicated annotation protocols and training datasets, often across multiple MRI sequences. Yet many oncology AI projects begin with only a few dozen inconsistently labeled studies, creating a data bottleneck long before model development becomes the challenge.
2. Sequence specificity– not all MRI annotations are equivalent
Annotating oncology MRI requires sequence-specific expertise. A T2-weighted prostate MRI demands knowledge of PI-RADS criteria, prostate zonal anatomy, and how clinically significant cancer appears across T2, DWI, and DCE sequences. Similarly, breast DCE-MRI annotation requires understanding enhancement kinetics and lesion morphology. These nuances cannot be captured through annotation guidelines alone. Reliable oncology MRI annotation requires radiology-trained specialists with expertise in the relevant subspecialty.
An MRI annotation vendor that cannot distinguish T1 post-contrast from T2 fluid signal, or that applies RECIST to an MRI without adapting for the modality, will produce training labels that encode systematic errors. Models trained on those labels learn the errors.
3. Consistency across sites and scanners
AI MRI cancer detection models fail to generalize when trained on data aggregated across sites without harmonized annotation protocols. A tumor boundary drawn at the enhancing rim at one institution may be drawn at the gross tumor volume at another. A PI-RADS 4 lesion annotated by one radiologist may not match a PI-RADS 4 annotation from a different institution’s convention.
The solution is not to exclude multi-site data; multi-site data is essential for generalization. The solution is centralized annotation with a single harmonized SOP applied across all sites, regardless of where the imaging was acquired.
4. Longitudinal annotation is the hardest problem in MRI AI data
MRI-based treatment response assessment, the clinical use case with the highest commercial and clinical value, requires longitudinal annotation: the same patient imaged at multiple timepoints, with annotations that are consistent across baseline, interim, and follow-up scans.
Longitudinal MRI annotation requires registration-aware review (ensuring annotations are spatially aligned across timepoints), temporal consistency checks (tumor boundary criteria must not drift between annotators or timepoints), and protocol documentation maintained across months or years of data collection. This is the least frequently executed well in oncology AI programs, and the most consequential for response assessment model performance.
MRI annotation across oncology tumor sites
The annotation requirements vary significantly by anatomy and clinical indication:
- Brain MRI: GBM and lower-grade glioma segmentation on multi-parametric MRI (T1, T1-CE, T2, FLAIR). BraTS criteria provide a framework, but application requires neuro-radiology expertise. Pseudo-progression and radiation necrosis differentiation on DCE-MRI is an advanced annotation challenge.
- Breast MRI: Lesion segmentation on DCE-MRI with kinetic curve annotation, background parenchymal enhancement grading, and multi-focus lesion handling. Response assessment requires consistent delineation across neoadjuvant chemotherapy timepoints.
- Prostate MRI: PI-RADS lesion annotation on bi-parametric (T2 + DWI) or multi-parametric MRI. ADC measurement in index lesions, transition zone versus peripheral zone anatomy, and correlation with targeted biopsy results.
- Liver MRI: LI-RADS criteria for hepatocellular carcinoma, arterial phase enhancement annotation on DCE-MRI, washout appearance, and portal hypertension markers.
- Rectal and pelvic MRI: T-staging, mesorectal fascia involvement, EMVI annotation for rectal cancer. MRI tumor regression grade for response assessment post-neoadjuvant treatment.
The multimodal integration requirement
AI MRI cancer detection rarely operates in isolation. In multimodal oncology AI, MRI annotations must be semantically compatible with PET/CT annotations, whole slide image (WSI) pathology labels, and genomic biomarker data. This creates a cross-modal consistency requirement that is distinct from within-modality consistency.
For example, a model predicting EGFR mutation status from MRI texture features, a radiogenomics application, requires MRI annotations that spatially correspond to the tissue regions from which genomic data was derived. Annotation mismatches between the MRI and biopsy spatial coordinates make the multimodal signal uninterpretable.
Measuring inter-rater reliability (IRR) across modalities, not just within each modality separately, is a prerequisite for building a multimodal oncology AI program on annotation data that reflects a consistent biological signal rather than systematic labeling artifacts.
Building annotation infrastructure for AI MRI cancer detection
The teams that build clinically deployable MRI AI models share a common infrastructure pattern:
- Data audit before model development: Audit existing MRI data for volume, sequence completeness, annotation status, and protocol consistency before writing training code. Most programs discovered through audit that their available annotated data covers 20–30% of the cases they believed they had.
- Annotation SOPs before annotation execution: Define boundary criteria, sequence hierarchy (which sequence is primary for each structure), handling of partial volume effects, and longitudinal consistency rules before a single annotation begins.
- Modality-specialist annotators: Annotators for oncology MRI must have radiology training in the relevant subspecialty. Generic annotation labor cannot annotate DCE-MRI kinetics or DWI ADC measurements reliably.
- IRR measurement across sequences: Inter-rater reliability must be measured across MRI sequences, not just overall. T2 annotation consistency and DWI annotation consistency are different clinical skills and may differ significantly within the same annotation team.
Pareidolia Systems – MRI oncology annotation expertise
We annotate across the full MRI modality stack: T1, T2, DWI, DCE-MRI, and multi-parametric MRI across tumor sites, including brain, breast, prostate, liver, and rectum. Our QC process maintains cross-timepoint and cross-site annotation consistency for longitudinal oncology AI programs. Pareidolia Systems to discuss your AI MRI cancer detection data program.
Conclusion
AI MRI cancer detection is limited not by deep learning architecture but by the quality, consistency, and depth of MRI annotation that training datasets contain. Volume gaps, sequence-specific annotation errors, cross-site inconsistency, and failed longitudinal annotation programs are the structural causes of MRI AI models that fail to generalize beyond the training institution.
Closing the imaging data gap requires an annotation infrastructure built to the same standard that clinical radiology demands: subspecialty expertise, systematic protocol, and rigorous quality control. Programs that invest in annotation rigor early build models that generalize. Programs that do not will rebuild their datasets.