 Mar 25 2026
Mar 25 2026 Scientific
Scientific
Mastering Medical AI Development: The Role of Manual Segmentation & Expert Review
The promise of artificial intelligence in healthcare is extraordinary — systems that can detect tumors earlier than the human eye, flag subtle pathologies in cardiac MRIs, or complex anatomical structures in seconds. But behind every breakthrough model lies an unglamorous, painstaking, and absolutely non-negotiable process: Manual segmentation and expert clinical review.
At Pareidolia, we work at the intersection of clinical science and machine intelligence. We’ve seen firsthand that the difference between a clinical-grade AI model and one that fails in deployment almost always traces back to the quality of its training data — and specifically, to how that data was labeled.
This blog unpacks why manual segmentation remains the gold standard in medical image annotation, what expert review actually entails, and how together they form the backbone of robust medical AI development.
- ~80% of AI failures in healthcare stem from poor training data quality.
- 3–5× more accurate outputs from expert-reviewed vs. crowd-sourced annotations.
- FDA requires documented validation and clinical review for AI/ML-based SaMD.
What Is Medical Image Segmentation?
Medical image segmentation is the process of delineating specific regions of interest — organs, lesions, tumors, vessels — within imaging modalities such as CT, MRI, X-ray, ultrasound, and histopathology slides. Segmentation is not merely “drawing around stuff.” It is a structured, medically meaningful act that defines the ground truth from which all downstream AI learning flows.
There are two primary types relevant to medical AI:
Segmentation Types in Medical AI
- Semantic Segmentation — assigns a class label to every pixel. Critical for organ delineation and tissue classification.
- Instance Segmentation — distinguishes individual instances within a class. Vital for oncological applications and polyp detection.
- 3D Volumetric Segmentation — extends 2D boundaries into 3D space across DICOM stacks. Used in surgical planning, radiotherapy, and longitudinal disease tracking.
- Landmark Annotation — points or keyframes identifying anatomical landmarks for registration, alignment, and measurement workflows.
Why Manual Segmentation Still Reigns Supreme?
With the rise of semi-automated and AI-assisted annotation tools, a natural question arises: can we skip manual segmentation? The short answer is no — at least not at the training data creation stage.
Automated pre-segmentation tools can accelerate workflow, but they introduce systematic errors that, if uncorrected, get baked into the model during training. A model trained on imperfect ground truth learns to replicate those imperfections, including missed pathology boundaries, false inclusions, and anatomically incorrect delineations. Manual segmentation by trained clinical annotators, particularly those with clinical or radiological background ensures that:
Why Human Annotation Matters?
Pathological edge cases and ambiguous boundaries are handled with domain reasoning, not algorithmic approximation. Anatomical context is preserved — what looks like noise to an algorithm is recognizable structure to a clinician. Rare disease presentations, artifact-prone scans, and low-contrast regions are correctly handled. Annotation guidelines can be applied consistently, reducing inter-annotator variability.
The Expert Review Layer: Non-Negotiable for Clinical AI
Manual segmentation by trained annotators is necessary — but it’s not sufficient. For AI models intended for clinical use, expert review — typically by board-certified radiologists, pathologists, or relevant clinical specialists — represents the critical quality gate.
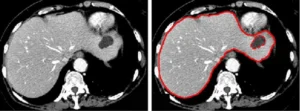
Expert review in the context of medical AI training data serves multiple roles:
1. Ground Truth Validation
Experts confirm that annotations are anatomically accurate and medically appropriate. They correct systematic errors, resolve ambiguous cases, and provide the definitive label where annotator consensus fails. This produces a high-confidence ground truth dataset that regulatory bodies, including the FDA under its AI/ML-based Software as a Medical Device (SaMD) framework, expect to see documented.
2. Ontology Alignment
Clinicians ensure that annotation ontologies — the structured vocabularies and classification systems used — align with clinical standards such as RadLex, SNOMED CT, or disease-specific grading criteria (e.g., BI-RADS for breast imaging, RECIST for tumor measurement). This is essential for models that will eventually be integrated into electronic health record ecosystems or decision-support pipelines.
3. Edge Case Curation
Expert review is particularly powerful in identifying and correctly labeling hard cases — scans where pathology is subtle, overlapping, or atypical. These edge cases, properly labeled, are often the most valuable training examples for improving model robustness and generalization.
4. Bias Detection
Clinical reviewers can spot demographic, scanner, or acquisition biases in datasets that non-clinical annotators and automated tools might miss. A radiologist reviewing CTs will notice if a dataset skews toward a particular scanner manufacturer, patient age band, or disease stage — biases that, unaddressed, produce models that underperform in real-world deployment.
The End-to-End Medical AI Annotation Pipeline
At Pareidolia, our medical data annotation pipeline is designed to maximize both efficiency and clinical fidelity. Here’s a typical workflow for a radiology AI development project:
1. Data Ingestion & DICOM Preprocessing
Raw imaging data (CT, MRI, PET) is ingested, de-identified under HIPAA/GDPR protocols, and pre-processed — windowing, resampling, normalization — to ensure annotator consistency across scanner types and acquisition protocols.
2. Annotation Guideline Development
Clinical experts collaborate with AI engineers to define precise segmentation protocols: inclusion/exclusion criteria, handling of partial volumes, approach to ambiguous cases, and inter-annotator agreement thresholds.
3. Primary Annotation (Manual Segmentation)
Trained medical annotators perform initial segmentation using specialized tools (ITK-SNAP, 3D Slicer, or proprietary platforms). AI-assisted pre-labeling may accelerate initial boundary proposals, but all outputs are manually refined.
4. Inter-Annotator Analysis
Dice Similarity Coefficient (DSC), Hausdorff Distance, and Cohen’s Kappa are computed to quantify annotator consistency. Cases falling below the threshold are flagged for adjudication.
5. Expert Clinical Review & Adjudication
Board-certified specialists review all primary annotations, correct errors, resolve disagreements, and sign off on final ground truth masks. This is the critical quality gate before data enters model training.
6. Dataset Versioning & Audit Trails
All annotation changes, reviewer decisions, and data lineage are logged. This documentation is essential for regulatory submissions and model performance audits — especially under the FDA’s Predetermined Change Control Plan (PCCP) framework.
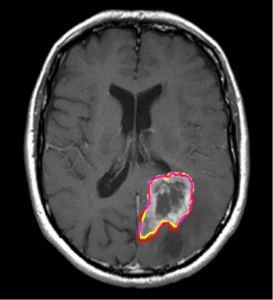
Regulatory Implications: Why This Matters Beyond Accuracy
The FDA’s AI/ML SaMD action plan and the EU AI Act both place significant emphasis on data governance and training data quality for high-risk AI systems, which includes virtually all clinical diagnostic and treatment-planning AI. Documented, expert-reviewed annotation workflows are not simply best practice; they are increasingly a regulatory necessity.
Specifically, the FDA expects sponsors to provide:
FDA Expectations for AI Training Data
- A clear description of the data collection, curation, and annotation methodology.
- Evidence of clinical expert involvement in ground truth creation.
- Inter-annotator agreement statistics and adjudication protocols.
- Data diversity analysis — coverage of patient demographics, disease severity, and imaging conditions.
- Version-controlled, auditable annotation records that can be reviewed post-market.
Companies that invest in rigorous manual segmentation and expert review from the outset are far better positioned for regulatory clearance — and, more importantly, for deploying AI that clinicians and patients can actually trust.
Common Pitfalls and How to Avoid Them
Having worked on dozens of medical AI annotation projects, our team at Pareidolia has seen recurring patterns that derail otherwise promising initiatives:
The Future: AI-Assisted Annotation with Human-in-the-Loop
The field is moving toward AI-assisted annotation pipelines where foundation models generate initial proposals that human experts then refine and validate. This hybrid approach has the potential to significantly reduce annotation time while preserving clinical accuracy — provided the human-in-the-loop layer is genuinely expert and not merely perfunctory.
At Pareidolia, we are actively integrating active learning frameworks into our annotation workflows — where the model itself identifies the cases it is most uncertain about, routing them to expert review first. This prioritization ensures that clinical specialist time is focused exactly where it delivers the most value: on the cases that matter most for model improvement.
Conclusion: Annotation Quality Is the Competitive Moat
The medical AI market is maturing rapidly. As foundation models become commoditized and compute costs fall, the sustainable differentiator for any medical AI company will not be the architecture of its neural network — it will be the quality of its training data.
Manual segmentation performed by domain-trained annotators, reviewed and validated by clinical experts, underpinned by rigorous quality metrics, and documented for regulatory purposes: this is the unglamorous but indispensable infrastructure on which clinical-grade AI is built.
At Pareidolia Systems, this is not just a workflow — it is our core conviction. If you’re building medical AI and want to talk about annotation strategy, regulatory positioning, or expert review pipelines, we’d love to connect.
Build Medical AI That Clinicians Trust
Partner with Pareidolia for expert-grade annotation, clinical review, and AI development for radiology, pathology, and beyond.