Mar 4 2026
Mar 4 2026 advanced imaging AI
advanced imaging AI
Beyond the Code: Why the Best Medical AI is Built on Variety Data, Not Just Volume Data
In the global race to build smarter healthcare AI, one assumption has dominated almost every boardroom conversation and research paper: more data equals better Medical Imaging AI. Feed the algorithm a million CT scans, and it will learn to diagnose. This logic feels intuitive, and in domains like consumer recommendation engines or language models, volume does correlate with performance.
Medical imaging AI is different in every meaningful way. Models trained on massive but narrow, homogeneous datasets consistently collapse in real clinical environments. The reason is almost always the same: developers optimised for volume while ignoring the property that actually drives generalisation and regulatory approval — variety.
This blog examines why data variety is the decisive differentiator in medical AI development, how global regulatory bodies FDA, CE Mark, CDSCO, CIDESCO, TGA, PMDA, ANVISA, Health Canada, IMDRF, and WHO, have embedded data diversity requirements into their approval frameworks, and what this means practically for AI developers building the next generation of clinical decision support tools, radiology AI, and SaMD (Software as a Medical Device).
“The reliability and success of any AI model are directly proportional to the integrity of its training data.” — Pareidolia Systems LLP
The Volume Trap: Why Big Data Thinking Fails in Radiology AI
The volume trap is seductive. Deep learning models have more parameters than older statistical approaches, and more training examples generally stabilise those parameters. But this relationship between volume and performance has a crucial hidden condition: the data must be representative of the deployment environment.
A chest CT acquired on a GE LightSpeed 64-slice scanner with a lung protocol at a tertiary teaching hospital in Mumbai looks fundamentally different from one acquired on a Siemens SOMATOM Force at a community radiology clinic in Berlin — even when both contain identical pathology. Slice thickness, reconstruction kernel, noise characteristics, contrast timing, patient positioning, and post-processing all vary. A model trained exclusively on one scanner type at one institution learns the imaging signature of that system. It has not learned of the disease.
This is the phenomenon researchers call domain shift — and it is responsible for the well-documented finding that radiology AI models trained at single institutions show performance degradations of 20 to 40 percentage points when evaluated at external sites. No amount of additional single-source volume can fix domain shift. Only variety can.
What “Variety” Actually Means Across Medical Imaging AI
When Pareidolia Systems LLP talks about variety in AI-ready medical imaging datasets, we mean systematic diversity across six critical axes:
1. Clinical Variety — Full Disease Spectrum
Real pathologies do not present uniformly. Radiology AI training data must include early-stage findings, late-stage presentations, atypical disease morphologies, incidental discoveries, rare subtypes, and cases complicated by comorbidities. A diabetic retinopathy detection model trained only on classic presentations will systematically miss the nuanced early vascular changes that matter most for preventive care.
Pareidolia’s annotation of medical images spans diverse pathologies — from coronary artery calcification and obstructive hydrocephalus to complex multi-organ segmentation tasks — precisely to ensure this clinical breadth in every dataset delivered.
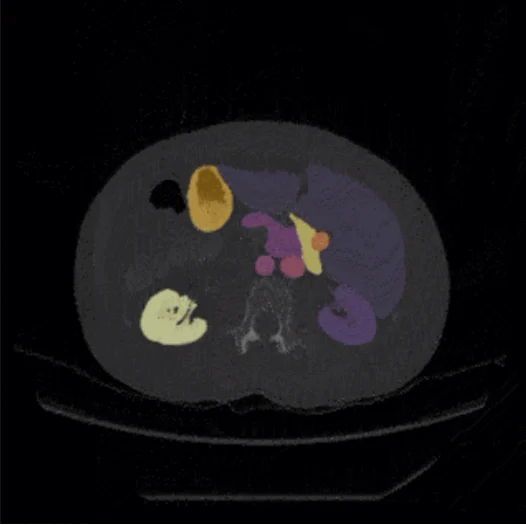
2. Technical Variety — Modalities, Scanners, Protocols
CT, MRI, PET, X-ray, ultrasound, CBCT, OCT, digital pathology, and fluoroscopy each capture different biological signals through different physical mechanisms. Models intended for multi-modal deployment must be trained on data from all relevant modalities. Even within a single modality, scanner manufacturer, hardware generation, field strength (for MRI), kVp and mAs settings (for CT), and contrast agent protocols introduce measurable image-level variation that must be represented in training data.
3. Demographic Variety — Age, Sex, Ethnicity, Body Habitus
Patient demographics directly influence imaging appearance. Bone density differs between paediatric, adult, and geriatric patients. Cardiac geometry varies with sex. Abdominal fat distribution affects organ visibility on CT. Ethnic variation in disease prevalence and genetic phenotype produces measurable differences in imaging presentation across populations.
Demographic homogeneity in training data is not just a performance problem — it is a health equity problem. Algorithms that perform worse for underrepresented demographic groups deliver inequitable care, create legal liability, and increasingly attract regulatory sanctions. FDA, CE Mark, and CDSCO all now require subgroup performance analysis precisely because demographic bias in AI is a patient safety issue.
4. Geographic & Institutional Variety
Disease prevalence, genetic predispositions, clinical practice standards, and available imaging equipment differ significantly by region. An AI algorithm built exclusively on US hospital data and validated only in North American academic medical centres cannot be safely deployed in India, Southeast Asia, sub-Saharan Africa, or Latin America without additional geographic validation.
For AI developers building global products, this has direct commercial implications. Regulatory bodies in each market — CDSCO in India, ANVISA in Brazil, PMDA in Japan, TGA in Australia, and Health Canada are moving toward requiring local patient population data for market approval.
5. Annotator Variety — Multi-Reader Expert Consensus
Ground truth derived from a single annotator carries individual cognitive bias. Robust annotation requires multi-reader frameworks where multiple qualified experts independently annotate a representative case set, inter-reader agreement is quantified, and cases with high disagreement trigger structured clinical review rather than being silently averaged.
Pareidolia’s expert annotators are regularly trained, clinically aware, and matched to domain complexity — ensuring that annotation teams working on cardiac MRI segmentation bring relevant cardiovascular imaging knowledge, while those working on retinal OCT annotation bring ophthalmic expertise.
6. Acquisition & Protocol Variety
Beyond scanner type, acquisition protocols, contrast timing, patient preparation, imaging plane, slice thickness, and field of view produce clinically meaningful image variation. SOP-driven annotation workflows must account for this variation by including protocol metadata in dataset documentation and ensuring training data includes the protocol range the deployed model will encounter.
The Ground Truth Problem: When Volume Without Expertise Fails
The explosion of automated annotation tools has made it easy to generate labels at scale. But in medical imaging, a label is only as valid as the clinical knowledge behind it.
Consider the segmentation of a pulmonary nodule on a chest CT. The boundary between the nodule and the adjacent parenchyma is not geometrically obvious. Is the ground-glass component included? How is pleural attachment handled? What constitutes the margin of a spiculated lesion? A fellowship-trained thoracic radiologist brings subspecialty knowledge to these decisions that a generic image labeller cannot replicate.
Poorly annotated data propagates labelling errors through model training. Models trained on noisy ground truth learn to replicate annotation errors at scale and may still achieve acceptable benchmark accuracy on similarly noisily labelled test sets, making the problem invisible until clinical deployment exposes it. This is precisely why radiologist-led quality assurance, multi-stage quality review, and clinically informed annotation practices are not optional premium features. They are the foundation of trustworthy medical AI.
High-quality annotation ensures your AI system is safe, trustworthy, and ready for real-world deployment. — Pareidolia Systems LLP
Global Regulatory Requirements for Data Diversity
This is where data variety transitions from best practice to compliance mandate. Regulators across the world have grown sophisticated in their understanding of AI/ML-based SaMD. Their guidance documents consistently emphasise data diversity — and the consequences of ignoring it are rejection, costly remediation, and in the worst cases, patient harm.
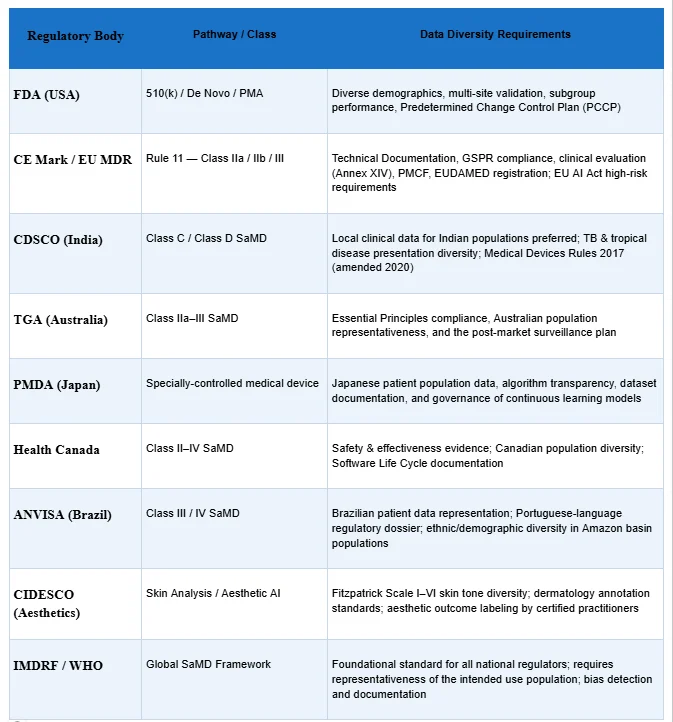
The pattern across all regulators is consistent: data diversity documentation is a core submission requirement, not an afterthought. Regulators ask: Does this model work for patients who look different from your training set? Does it perform consistently across imaging protocols you did not control? Does it maintain performance across the demographic range of your intended market?
The Business Case for Variety-First Development
Beyond compliance, data variety is a strategic competitive advantage with direct commercial implications:
Faster Regulatory Clearance
Submissions with well-documented, diverse datasets move through FDA, CE Mark, and CDSCO review faster because they preempt reviewer questions. A dossier that proactively demonstrates subgroup performance, multi-site validation, and geographic representativeness signals development maturity.
Larger Addressable Market
An algorithm validated only on US hospital data cannot be marketed simultaneously in Europe, India, Japan, and Australia. Every additional geography adds validation cost when approached sequentially. Multi-geography development from the start opens global markets simultaneously — a significant commercial advantage over single-market competitors.
Reduced Remediation Cost
Retrofitting demographic or geographic diversity into a dataset after model training is expensive and often requires rebuilding the entire pipeline. Building variety from day one is always cheaper than fixing homogeneity after a regulatory rejection.
Clinical Adoption
Even cleared algorithms can fail to achieve clinical adoption if radiologists and clinicians do not trust them. Trust is built through demonstrated generalisation across patient populations, scanner types, and clinical environments — which is only possible when variety was built into the development dataset.
Ethical & Reputational Protection
Biased medical AI that performs worse for underrepresented demographic groups creates ethical liability and reputational risk. Building variety-first is the most reliable path to equitable AI that serves all patient populations.
What Variety-First Development Looks Like in Practice
Translating the variety imperative into operational practice requires a structured approach across the full dataset development lifecycle:
- Step 1: Define the deployment environment before defining the dataset — map intended countries, clinical settings, scanner types, patient demographics, and disease spectrum before acquisition begins.
- Step 2: Design multi-site, multi-geography data collection from the start — single-institution data pipelines are structurally incapable of producing the variety required for global regulatory approval.
- Step 3: Match annotators to domain complexity — cardiac MRI annotation requires cardiovascular imaging expertise; retinal OCT annotation requires ophthalmic expertise. Pareidolia’s cross-domain teams spanning multiple medical specialties are built for this exact requirement.
- Step 4: Implement inter-rater agreement monitoring with Cohen’s Kappa, Dice coefficient, or Intraclass Correlation Coefficient — cases with high disagreement trigger clinical review through structured SOP-driven workflows.
- Step 5: Document data diversity decisions in regulatory-submission format — demographic distributions, site characteristics, acquisition parameters, annotator qualifications, and quality review outcomes must all be documented proactively.
- Step 6: Plan for post-market data diversity monitoring before the first regulatory submission — FDA, CE MDR, and PMDA all require ongoing performance monitoring infrastructure.
Pareidolia Systems LLP: Empower for Variety-First Medical Imaging AI Development
Pareidolia Systems LLP is a specialised B2B medical imaging data annotation & segmentation partner positioned at the critical intersection of advanced technological expertise and stringent clinical precision. Our services are engineered to deliver the data variety that modern medical AI development requires:
Medical Image Segmentation
Pixel-accurate segmentation across CT, MRI, PET, ultrasound, X-ray, and digital pathology. Domain-driven annotation workflows covering organ, lesion, vessel, and disease pathology segmentation with multi-layered quality assurance in medical imaging. AI-ready output formats suitable for all major machine learning frameworks.
Annotation of Medical Images
Comprehensive medical image labeling services — bounding boxes, polygons, keypoints, semantic masks, measurement tasks, and complex multi-class annotations. Expert annotation spanning coronary artery calcification, obstructive hydrocephalus, and hundreds of other disease patterns. Multi-modal support across X-ray, CT, MRI, ultrasound, and digital pathology.
3D Model Creation | Medical Imaging AI
High-fidelity 3D medical reconstruction from CT, MRI, PET, and ultrasound data. Anatomically precise volumetric models for surgical planning, medical education, clinical research, and AI model development. Deep expertise in vascular 3D models from CECT and NCCT studies — critical for cardiovascular AI applications.
Quality Control in Medical Imaging AI
End-to-end QA protocols encompass image quality assessment, annotation consistency review, dataset balance auditing, and regulatory audit readiness. Radiologist-led quality assurance with human-in-the-loop validation, ensuring every delivered dataset meets medical-grade AI standards.
Cross-Domain Specialty Expertise
Pareidolia’s annotation teams cover all ten major Medical Imaging AI specialties: Radiology, Cardiology, Neurology, Pulmonology, Ophthalmology, Musculoskeletal, Gastroenterology, Nephrology, Dental, and ENT. This breadth is not incidental — it is the structural foundation for delivering the clinical variety that regulatory-ready AI requires.
Conclusion: Build for Variety, Win in the Real World
The medical AI models that will define the next decade of healthcare are not being built on the largest datasets. They are being built on the most thoughtfully constructed datasets where demographic representation, geographic range, imaging modality breadth, disease spectrum coverage, scanner diversity, and subspecialty-expert ground truth were treated as design requirements from day one, not compliance checkboxes added before submission.
Volume is table stakes. Variety is the differentiator.
For developers building radiology AI, SaMD, clinical decision support, or aesthetic medicine AI: the path to FDA clearance, CE marking, CDSCO registration, TGA approval, and clinical adoption runs directly through data diversity. The regulators know it. The clinical evidence knows it. The deployment failure statistics know it.
Pareidolia Systems LLP exists precisely at this intersection, combining clinical precision, cross-domain expertise, SOP-driven annotation workflows, and platform-agnostic delivery to help AI developers build the variety-first datasets their models need to work in the real world.
We Annotate. You Innovate. — Pareidolia Systems LLP!
Ready to Build Variety-First AI Datasets?
Contact Pareidolia Systems LLP for a free consultation or demo.
Follow us: LinkedIn | Instagram | Facebook | X (Twitter) | YouTube